

Straight Talk About Ancestry and DNA
Ancestry results from DNA analysis can be confusing. This guide explains the background, the techniques in use, and how to interpret the results sensibly.

Today was my birthday. I am now thirty-five years old. I’m as surprised as you are that I made it to 35 years old.
This is a cross post with Traitwell.com. It was written by my colleague Gavan Tredoux with some light editing by yours truly.
We recently released our Traitwell Ancestry report. Please check it out for yourself.
If you've already gotten your DNA tested by 23andMe, AncestryDNA, MyHeritage, Living DNA, or Family Tree DNA, you can upload your raw DNA file to DNA Ancestry Analysis to get your results for free.
Introduction.
People are enthusiastic about genealogy and tracing their “roots.” There are few pastimes more popular on the internet. Its popularity extends far beyond that; it is so pervasive all over the world and over time that it seems interest in “roots” is a core part of human nature itself. But how useful really is DNA for tracing “roots”? Are the results that you get meaningful? What are “roots” anyway?
The first thing that seasoned consumers of “ancestry” services notice is that the results they get, the terms and groups that are mentioned, differ a lot. We hear of Europeans, Africans, Mediterranean types, Middle Easterners, Amerindians, Siberians, East, South and West Asians and so on. The terms change between different services. They mutate over time, tracking the winds of fashion. You may be told that you are 5% of one and 25% of another. But 5% of what, exactly? With different group names, the percentages may simply change. They may change if you use the same terms but a different ancestry service. This variation is inherently confusing. It is important to grasp the underlying principles firmly.
Synonyms and Euphemisms.
Confusion starts with the concept of “ancestry”, which coexists with a number of related terms, which are used loosely and euphemistically: “roots”, “culture”, “ethnicity”, “origin”, “heritage”, “demographic”, “nationality”, and many others. Keeping clear distinctions between these is necessary. And no debate was ever really settled, or any inquiry ever been advanced, by relabeling (whatever Mills, Barban, and Tropf 2020 may say otherwise).

Some examples will help. Supposed geographical origin is often used here: African versus European versus Asian, and so on. But you may have been born in Australia. To recent immigrants from the Levant. This regional grouping also lumps together North African with Sub-Saharan African, but that is very misleading. North Africa and Europe were united by the Mediterranean Sea and colonized extensively over many years. Thus Cleopatra, often thought of as an Egyptian, was a Greek by descent. The important barrier for intermixing was the Sahara desert, much more formidable than the Mediterranean for most of human history. Remote colonization is hardly unknown throughout human history, which has no reason to respect physical contiguity other than logistical difficulty. The facts of human migration are badly served by geographical terms like this. Most people would not be happy with so crude a distinction. There is too much information loss, an idea we will return to.
“Culture” and “ethnicity” refer to many attributes—religion, language, accent, dress, literature, song, humor, the list is nearly endless—which are learned. You are born into a context in which you learn and adopt those attributes. It is possible to be adopted into an ethnic group as an infant and acquire its characteristics simply by learning them. That kind of adoption is relatively rare historically but not unknown. For example, after WWII many South Korean infants were adopted and raised by Americans, and are culturally indistinguishable from other Americans. But if they have their DNA tested they will not match their adoptive parents. This connection is why any talk about things that can be learned, or which may change fundamentally over time, is misleading when applied to genetic differences.
Let’s establish a basis for the rest of this discussion. We are talking about genes here, as revealed by DNA sequencing. You are born with those genes, as were your ancestors, in different proportions. We need a name for a group which has been defined on the basis of genes. It turns out that the most convenient name—arbitrary so long as it is not confusing—is exactly the name that Charles Darwin used, and is still in wide popular use today: race. As in On the Origin of Species by Means of Natural Selection, or the Preservation of Favoured Races in the Struggle for Life (1859). For Darwin, a race was a breeding group. Though he did not have our modern concept of genes, he did understand that there were ‘hereditary particles’, and that groups of people who mate among themselves will end up sharing these, regardless even of how they start out. It is a very flexible idea in his hands. Darwin’s ‘race’ may be small in numbers or large, and is certainly not limited to ‘blacks’ versus ‘whites’.
The size of the races you care about is a function of how fine a resolution you want to operate at. At a gross level we might distinguish Martians from Earthlings. Or “blacks” from “whites.” Or Amish from Hutterite, Chinese from Dravidian. Any breeding group will do, as long as it really is (or has been) endogamous, so that it marries within the group (though no group is absolutely so in practice). The choice of resolution is arbitrary, just like the resolution of a microscope. Nor is there some predefined pantheon of races, to which one must be limited, though common usage has established a few lists which may be useful for communicating with others, but are not mandatory. By analogy, there are lots of named mountain ranges, but we may talk of other mountains too. It’s a general concept, without any definitive taxonomy.
Reproductive Isolation.
How do races arise? A degree of reproductive isolation is essential here. In the past this may have been imposed by physical separation and often was. The further back in time you go, the more important these geographical barriers and dispersal were for separation. Consider the ‘Old World’ versus the ‘New World’, isolated from each other for perhaps 15,000 years. But that is not necessary, since even people who live close together need not interbreed in practice. This fact is true of all species, for whom the question is nor whether they can interbreed, but rather whether they do interbreed, and to what extent. For humans there are really two forces at work here:
A migration event may selectively sample from a host population, so that those who emigrate elsewhere may start out different to a degree.
Even if an offshoot is a perfectly representative sample, over time genetic drift—the accumulation of small mutations by chance—will accumulate steadily in both groups and separate them.
Only selection against those genetic differences, because they are harmful, can make the two populations converge (the first case) or keep them from separating (the second case). Historically a combination of forces has ensured that things stay interesting. Migrants, never a representative sample, leave and grow distinct over time, evolving elsewhere, possibly under selective pressure. Then they may come back again and mix it up over time, bringing novel genes with them which may prove useful. Or go elsewhere and mix with others, only to either vanish, and reappear much later, with the same effect. These demographic ebbs and flows leave their mark today as population structure (see Reich 2018 for recent work on this). That fundamental simplifying assumption of Population Genetics 101, random mating, is no more true than perfectly inelastic billiard balls in physics 101.
Barriers to out-marriage may be established using a large variety of criteria, reinforced by custom, habit and taboo. Ethnic markers are an important mechanism for doing this in practice, and include just about anything that can be learned by culture, as well as social-economic class. These markers are visible and can be detected with high reliability, whereas genes are cryptic, and we have only recently learned how to sequence them. For most of human history we could not do that. The markers used are inherently arbitrary and context-dependent.
Though language and religion can be markers, that depends. In Northern Ireland for example, religion is a very definite ethnic marker. Language is not, since almost everyone speaks English, though subtleties of accent are used. In another context, language may matter far more than religion. Cooking, dress, sense of humour, slaughtering rites, and many other markers have been and are used. Physical location can and often does serve as a simple proxy, but is accompanied by other tests.
A group which inbreeds using ethnic markers will inevitably become genetically distinct from its neighbors over time, making it racially different. There is a strong correlation between the two in practice, because adoption is rare and faking multiple ethnic markers is very hard. Just because something can be learned in principle (consider Beethoven’s concertos, or algebraic topology) does not mean that you will be able to learn it in practice (try faking a Belfast accent, or playing Beethoven passably).
Difference here is a matter of degree. Any such groups overlap. It may be a very fine degree of difference. Perhaps just one crucial gene frequency might be the difference. There is no way to legislate how much difference is required for that to be interesting. It depends on the questions at hand. For a condition like sickle-cell anaemia or lactose tolerance, one gene may be enough to be intensely interesting. That’s really how evolution works to begin with. Small changes propagate and grow over time. More often these groups differ in their frequencies of very many genes, a fact which is correlated with the group distinction. There is common confusion about this because of the influence of taxonomists, whose work is often represented as establishing definitive categories into which people may be placed. But even distinctions between species are not hard and fast. There is overlap. And they are devised by us, to help understand the world, they are not ordained by a higher authority or in any sense primordial. After all, they are always in flux, as selection pressures and drift operate.
“Racial purity,” a long discredited idea, is often raised here as a refutation of, or condemnation of interest in, human diversity. Given that races overlap, and are usually in constant flux, the idea makes little practical sense. A line of descent is considered ‘pure’ by animal breeders if it is highly inbred, causing it to approximately uniform internally. Variation is greatly reduced. This is seen in artificial examples like lab rats, which are specifically inbred over many tightly controlled generations to reduce their genetic diversity. It is possible, it has been done, it is useful, but humans do not breed like that, though they may become relatively more isolated than others. Iceland, for example, is rather more inbred than other European nations.
Other mechanisms then ethnic markers may be used to establish reproductive isolation. Though genes are cryptic, they sometimes leave visible traces, through skin color, body morphology, height and other physical characteristics. Unlike ethnic markers, these cannot be learned. Since they are in practice rarely clear-cut in all cases, ‘passing’ is possible for some people who are at the boundaries, and some physical manipulations are possible. The use of physical markers is so widespread that the concept of race is itself often confused with such physical characteristics, but they are conceptually separate and the difference is important. The markers should not be confused with the genetic grouping itself, which is more fundamental and can be discovered, as we explain below, using sequencing and measures of genetic difference which make no reference to the arbitrary markers themselves, physical or otherwise. Moreover, the racial group may have arisen using ethnic, entirely learned, markers, rather than physical markers.
There is no reason why various markers cannot be combined as the basis of breeding boundaries, and this is common. Visible markers like skin color and height may be combined with accent, dress, cuisine, class and profession. Aggregation of markers cancels out errors and raises the reliability of the distinctions made.
Information Compression.
Why should we classify people at all and use these labels? Is it not better to just treat everyone as individuals? After we are all interrelated, ultimately. The last argument is certainly true, but can be applied to any old distinction. Humans are related to everything else alive, if you go far back enough. That does not mean we should not distinguish them. Classification lies at the heart of all systematic biology. It also lies at the heart of chemistry and science as a whole, where that deals with the world we observe and its history. Again, it is true that thinking of people as members of groups loses a great deal of very specific information. Here resolution is everything.
An example from geography may be useful here. Do you live in the Mid-West, the East Coast, the West Coast, or the West? The boundaries are rather fuzzy, but still they are real. Not everybody agrees which places are included in those areas. You may prefer to lump the Mid-West with the West. Or you may want to split it into smaller pieces. Is Lexington, Kentucky, in the mid-west? It is certainly close, but most would say the South. Still, it is not arbitrary where places go. San Francisco is not in the Mid-West, at least, and St Louis is not on the East Coast—that would be crazy thinking.
At the right level of classification granularity, for the problem being considered, you are consciously discarding information that is specific, to gain strength from information that is derived from other members of the group you have placed the individual in. Classification is a form of information compression. Without that compression it is impossible to learn from a collection of individuals. If you are trying to find the cause of skin cancer, you have to learn over many examples of those who do, and those who do not, have the disease. When learning, you are temporarily ignoring their other distinctions, their undeniable uniqueness, and trying to pick out what they share. Doing a good job of that will determine your degree of success. It is impossible to learn anything at all about people if they are always and everywhere treated as unique individuals. One cannot say anything at all about them that is not just their personal history, which cannot generalize to others. Any specific details about individuals which are ignored in one classification system can just as easily be used in other systems, which pick them out if they are shared. Anything truly unique, which does not show up in any classification system, is probably just random noise and may be ignored.
There is no way to establish a hard and fast rule deciding what the right level of resolution is when dealing with genes. What are you trying to do? For some purposes, it may be acceptable to make gross distinctions by which all mankind is divided into only say four of five large groupings, or all humans are contrasted with insects. For other purposes, that may not be good enough. It may depend on the timeframe you care about, in which case distinguishing between hominid species may be important.
All these ideas apply acutely to personal ‘ancestry’. For most people, when your DNA is analyzed, very little if any DNA from your near relatives will also be available. The DNA of your close direct-line ancestors will almost certainly not be available either. What is available is DNA from people far more distantly related to you. Not your direct ancestors, nor your clan, but a few levels beyond. What is available must be analyzed and understood at the racial level, forming substantial groupings which extend far beyond families. Finding the right groupings is not straightforward, but it is not wholly arbitrary. There is a lot of relevant information in the genetic sequences already collected from millions of people.
If everyone throughout history had interbred randomly, the collection of their genes would be of a uniform consistency. They have not and it is not. Instead, it is like lumpy gravy, or a chunky stew rather than a puréed soup. There is structure concealed within it that can be revealed, and your own DNA can be related to that structure in all sorts of interesting and informative ways. The resolution at which this can be analyzed depends on the depth of the data collected. As more data gets added, the degree of resolution that is possible improves. This data doesn’t only include living individuals, but extends to archaeological findings. It will only grow richer over time.

So how many racial groups are there then? No definitive answer can be given. As we said, there is no pantheon of groups, no definitive list. With the data already at hand, hundreds can be identified. But that isn’t necessarily helpful. You may only be interested in major distinctions. Perhaps you only care about your Irish ancestry, as opposed to your German, and finer distinctions will bore you. The first step is to settle on the resolution that interests you most. Some experimentation may be needed to do that.
Genetic Distances and Components.
Sequences are a recent development, but population structure has been studied for much longer. The best technique available, before sequencing was invented, used blood groups, which are known to vary widely between races. Blood data was also widely available because of its use in medical applications (Cavalli-sforza 1994). Since blood groups are genetically controlled, they act as an inexact proxy for the much richer kind of analysis we can do now. Before blood groups, morphology (physical appearance, skull shape, height, bone lengths and so on) was used, and is also an inexact proxy for genes (Baker 1974).
At root, all attempts to understand structure within human populations rely on the idea of genetic distance, which can be calculated directly between any two sequences. Naively, one might just add up the differences at each position and use the score as the measure of distance. Fewer differences mean lower distance. Two identical sequences will have zero distance between them. The naïve approach can be improved in many ways, either by weighting some genes more than others, by completely excluding some genes from consideration and including others, to taste. Given a measure of distance it is possible to search for the ways in which some people are more similar to each other using it than they are to others. Two techniques are popular for this, usually in combination.
Cluster Analysis.
Cluster analysis tries to identify “clumps” or concentrations in the data. People assigned to a clump are thought to be closer to each other than they are to others. This is how we identify galaxies among all the stars, using spatial distance: the stars within each galaxy are closer internally to each other than they are to the stars assigned to other galaxies There are many established algorithms for automatically discovering the best fit of clusters to the set of data. Typically these require first deciding how many clusters you are interested in, that is your level of resolution. That’s a lot like deciding if you want to find galaxies (a coarse level) or solar systems (a fine level). A pragmatic way of deciding this is to start at the finest level (very many clusters) and seeing how repeated simplification adds explanatory power. If a further level of refinement doesn’t help, the process stops and settles for the current number of clusters. That parameter, the number of clusters, is commonly referred to as ‘K’.
Suppose you have to rake up a yard full of leaves, using a garden rake, a plastic shovel, and a wheelbarrow. You notice right away that the leaves are not randomly distributed, they are already concentrated more in some areas than others. Pushing a wheelbarrow is hard work, so you want to minimize that by only shoveling a few piles into your barrow. For that you need piles. You start by arbitrarily choosing spots to start raking the piles together. Places where they are already somewhat closer together are easier, so you form many little piles of leaves. Too many, so you decide to amalgamate them into a smaller collection of larger piles, raking together the little piles that are closest to each other. You continue for another few rounds of amalgamation, until you have a manageable set of piles you can wheel your barrow to and shovel. How many piles should you stop at? That depends on how well the amalgamation goes, how much energy you have, whether you prefer raking to shovelling. It is not worth amalgamating piles that are very far apart, that would take all day. It is easier to wheel to them and then shovel. There is a natural limit to all this: one giant pile, but that’s unlikely to happen.
In practice, finding the genetic “distances” you need for this can be simplified. Not all of the dimensions on which genomes depend are equally important. Some genes just matter less. By reducing the problem to only the important dimensions, you can cluster using just those. That’s a deliberate decision to sacrifice relatively unimportant information.
Principal Components Analysis.
Principal Component Analysis is a popular dimension-reduction technique (there are of course many others). It supposes that underlying the data there are hidden “latent” components (or factors) which explain the patterns observed in the data. Even though these factors are not directly observable themselves, they can be found using statistical techniques which look for similarities. When two things, say A and B, are similar in many respects, but not identical, and you are sure that neither directly causes the other to be similar, you should suspect that some third factor C, operating behind the scenes, makes them similar. That factor may not be observed directly, but it is highly unlikely that the similarity would just happen by chance—something must explain it, miracles are not allowed. Thus when two gene sequences are very similar (they correlate highly), it is reasonable to think there is a hidden factor behind both. For genes this is the idea that (unobserved) common descent explains the similarity, which cannot occur just by chance—the sequence is so long and detailed, that would be nearly impossible. A decision must be made about how many latent dimensions to entertain. Choosing many will permit finer resolution, but one can stop at the point where adding more factors adds little additional explanatory power, relying on Occam’s Razor: all else being equal (be careful here), simpler is better. Each of the dimensions which are retained is constructed as a weighted combination of the original ones: a lot of some, a bit of some others, a smidgen of a few. There is an objective, reliable, disciplined way to do this.
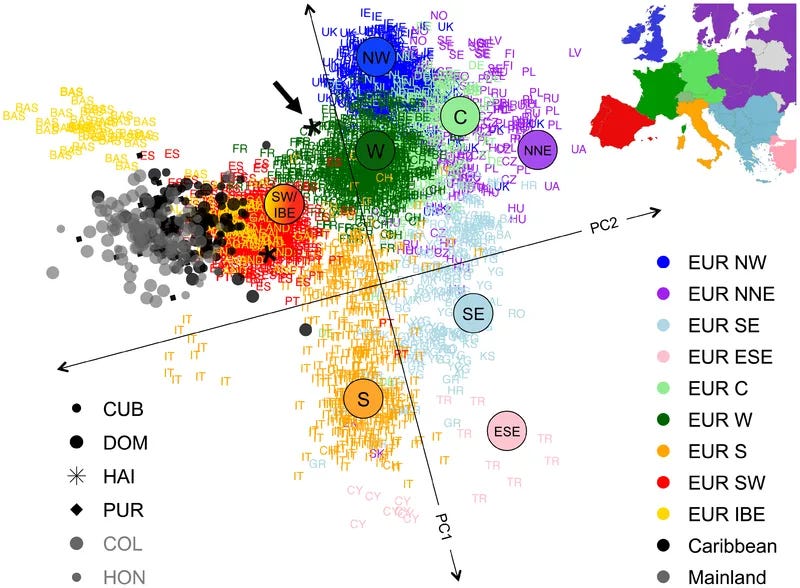
Once the dimensionality has been reduced to the most important components, cluster analysis can be used as explained above to find the groupings in the resulting ‘space’. Or one can just use inspection to form the clusters by hand, depending on how complicated it seems to be if, say, you settled on just two dimensions and laughed off the rest. By seeing which points are included in those clusters it is possible to assign labels which humans are able to interpret, given their experience of the world. At various levels of granularity there will be correspondingly more or less of these groups to label, by inspecting who was included in them. It may be necessary then to use geographical or other terms as good-enough names. Good-enough is the key point.
For both the above techniques, the choice of the number of dimensions and then clusters can be made by fiat. If you are conducting the analysis, it’s your choice after all. You can experiment and try more, or fewer. Perhaps you already have some idea of the granularity you prefer. If not, it will soon emerge as you experiment, and find that spot where the woods emerge from the trees. Ancestry services make these choices for you in practice, unless you have the skills yourself. The fact that they make different choices, and use different algorithms, means that you effectively have a lot of choice yourself, at one remove. That’s why results vary so much, and should be inspected skeptically, even compared with each other. The results are not arbitrary, but neither are they set in stone.
Groups and Labels.
How different are the groups we find using these techniques, really? Again that depends on the resolution chosen. At finer levels of resolution, more and more groups will be revealed which are quite close to each other, with only fine grades of distinction, approximating a continuum. That doesn’t mean there aren’t groups at that resolution with large distances between them, only that in-between those groups lie others, each of them close to each other. By taking a step back (lower resolution) the distance between all the groups can be increased. Note that differences here are deliberately not calculated using genes which have known effects, since that invites confusion from selection effects. Convergent evolution on genes subject to selection could make people in totally different parts of the world seem superficially similar, but not by descent. Tall Polynesians would be confused with tall Tutsis.
In practice, groups must be defined by analyzing large collections of genomes using statistical techniques like the ones described above, extending to many thousands of individuals. There are several long-running projects which have collected a great many of these genomes and made them available for researchers to analyze. They are continually enriched by more additions from contemporary donors and archaeological finds which have been sequenced. With larger collections it becomes more feasible to do very fine-scale analysis: more groups can be identified. Depending on your needs, that may or may not help you. Sometimes too much information is counterproductive.
Do these groups make sense in the real world though? That can be tested. In practice, it has been found that the groups we find using appropriate levels of granularity very closely fit the labels we use anyway, and have used for most of human history (see for example N et al. 2002). That matches common-sense. Another way to check this is to see if the groups predict real-world outcomes, like disease susceptibility. They do. Very well.

Finding Your Percentages.
Given a collection of racial groups, found using the above techniques, your particular genome can be used to calculate which ones you seem most similar to. Percentages can be assigned representing “how much” of your ancestry appears to derive from the group. Depending on the algorithm that was used, those percentages can be arrived at in different ways, but the underlying concepts are still common. Still it is wise not to place absolute faith in these calculations. They are, again, not arbitrary, but they are not set in stone and depend heavily on the data currently available, the algorithm used, and other assumptions. But they are always informative and fun!
At Traitwell, we just released DNA Ancestry Analysis, where you can switch between algorithms to see the changes in your genetic ancestry percentages.

It’s free to use if you already have data from 23andMe, AncestryDNA, Nebula Genomics, or just about any other DNA testing service. If you haven’t had your DNA tested, go ahead and order one of our sequencing test kits here.
Are the Results Important?
That’s up to you. Many, perhaps most, find them intriguing as a kind of personal history record. We don’t know much about our ancestors. Most of their records are gone and forgotten. Your racial affinities help to recover some of that information, a small contribution to the triumph of memory over forgetting. People tend to take pride in their “roots’’ and why shouldn’t they? That’s not for others to decide. Genealogy has always been enthusiastically pursued all over the world.
Aside from that, there are all sorts of scientific applications of such knowledge. Ethno-pharmacology, as it is misleadingly known (see above) is a burgeoning field. Depending on your racial connections, some drugs will work better for you than others. This is well-established. Those links have not become obsolete in the era of individual gene sequencing, because we usually do not know precisely which genes are individually involved in the different reactions to drugs. Race performs information compression for us and allows us to make useful choices despite not knowing which genes, exactly, it is encoding for. Maybe one day we will, but right now we don’t, for most things, and we want to do the best we can until we know better. Similar observations apply to a host of diseases which show different patterns of expression by race. It is the sort of knowledge that saves lives.
References
Baker, John Randal (1974). Race. London: Oxford University Press, 1974.
Cavalli-sforza, L. Luca (1994). The History and Geography of Human Genes. Princeton, NJ: Princeton University Press, 1994.
Mills, Melinda C., Nicola Barban, and Felix C. Tropf (2020). An Introduction to Statistical Genetic Data Analysis. Cambridge, MA: MIT Press, 2020.
N, Risch et al. (2002). “Categorization of humans in biomedical research: genes, race and disease”. In: Genome Biology 3.7 (July 1, 2002).
Reich, David (2018). Who we are and how we got here. Oxford: Oxford University Press, 2018.