

Beadle: AI for Genetics
The first-of-its-kind AI-powered chatroom for DNA, built by Traitwell


I recently offered to acquire 23 & Me with financing from friends of mine. I’ll have more on that soon.
This post, which is a Traitwell.com cross post, gives you a sense of what we are doing.
Beadle is Artificial Intelligence (AI) for genetics. It acts as an expert genetics counselling assistant. It helps you to understand and navigate a complex and subtle topic. Like all other AI tools it augments the abilities of those who use it. But unlike many other tools, it requires no special expertise to use straight away.
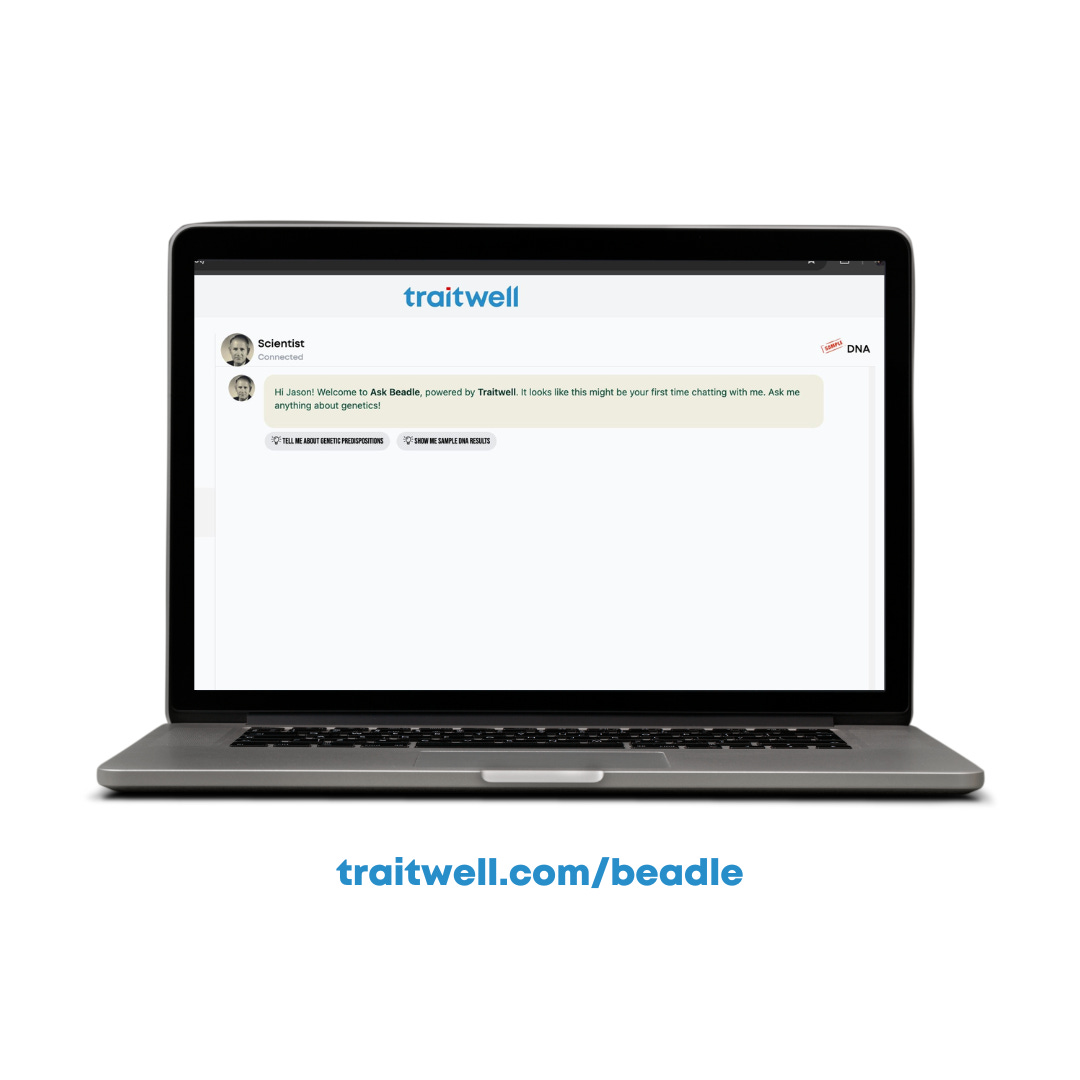
1 Getting Started with Beadle
DNA results can be complex. If you are presented with a long list of figures, percentiles and such, it can be intimidating making sense of them. Some things may be clear, others not so much. Often you have questions. Who to ask? Well, now you can ask Beadle.
Thanks for reading Traitwell! Subscribe for free to receive new posts and support my work.
Have more questions? Fire away, as many as you like. Get down and dirty with your own genome if want. Or branch off into other genetics topics, once your curiosity is piqued. Beadle is here to help you find out all about it, at your own pace, as simple or as complex as you like.
Don’t worry, Beadle isn’t going to tell on you. It’s all private, just between you and your genetics expert. Take as long as you like. Come back when you have more questions. Keep drilling down. This is a genetics assistant without helix-shaped strings attached. You will see a sample session below.

Figure 1: A basic Beadle Interaction.
These Q&A sessions accumulate as you ask more and learn more. Your can choose from multiple personae to interact with, one at a time or all together. The Scientist will give you lab-coat responses. The Enthusiast will get all excited and shout it from the rooftops (but only to you, of course). The Skeptic will level it up, pouring cold water on ambitious theories, finger-wagging about sample sizes and such. He’s not much fun that way. Customer Support will answer your questions about your account and how to use our system.
But you’re probably eager to kick the tires and give it all a go. You need an account though, so if you don’t have one, set it up now. It’s free and takes a few minutes. If you upload your DNA you can chat to us about it right away. If you don’t have your DNA done yet, order it from us and we’ll let you keep kicking those twirly-shaped tires using some generic sample DNA. Just to see how it all works.
Wait, we already know what you might want. You’re DNA-curious. “Can I improve my DNA scores?” Beadle’s not going to judge you about that. Nor is Beadle going to classify you, deny you, defy,...., well you get the idea. Instead, here’s what Beadle might say. Scientist speaking.
Your DNA scores are a reflection of your genetic predisposition and are effectively fixed; you cannot change your DNA itself. However, it’s important to remember that genetics is not destiny. Environmental factors, lifestyle choices, and personal behavior can significantly influence how these genetic propensities manifest in your life.
For instance, even if you have a higher genetic predisposition for alcohol use disorder, engaging in healthy lifestyle choices like moderate alcohol consumption, seeking early intervention if needed, and maintaining a supportive social environment can mitigate the potential impact of these genetic inclinations.
Think of your genetic scores as providing insights into areas where you might focus extra attention or preventative measures, not as a definitive prediction of your future.
Mind you, Beadle will only chat about genetics. Ask about that. If you want moral advice, you should get a pastor, a priest, or maybe a social scientist. Don’t ask about that. Else Beadle might get snippy.
2 A Brief History of AI: From Calculators to Beadle
Artificial Intelligence has been just over the horizon ever since the simplest mechanical calculator was invented centuries ago.1 It still is, but now we can see it peeping at us. Initial disappointment was inevitable. With every advance in computing, hopes were rekindled, only to be dashed all over again. As a result many in industry became so disillusioned with false promises that they paid little attention to the topic whenever it was raised. AI was all too easy to write off as just so much more ‘hot air’. Now it is no longer necessary to even define the acronym.
Two things have been slowly but exponentially building all along, barely noticed: scale and speed. A defunct economist—a large part of the world was once in thrall to him—wrote that enough change in quantity amounts to a change in quality. This served unintentionally as a birthday card to AI. Those advances in computing were building all along, but everyone was fated by relative frames of reference to see them small, not large. In the late 1950s statisticians might take 6 months to invert a large matrix. Today it can be done in nanoseconds. The ability to do these kinds of computations fast enough to use them in practice lies at the heart of the AI revolution.
Every part of the general computer revolution has been involved in this nascent emergence of AI. None is more important than the emergence of neural networks, a model of how neurons are understood to operate in (mostly) the brains of animals.2 These models, which operate without any theory about the domains they are applied to, were heavily promoted early on but took a long time to deliver on their initial promise as statistical learning mechanisms, overshadowed by more straightforward, better understood, techniques until quite recently.3 Many tinkered with neural nets, few reported unusual success not achievable more easily.
Things bubbled along incrementally without much fanfare until two developments sprang to the fore in the early 2010s. First, work in image recognition and classification showed that more complex ‘deep learning’ model-free multi-layer neural networks were, with sufficient data and computing power, noticeably better at learning than existing alternatives.4(Mutlilayer networks had been enabled by the invention of ‘backpropagation’ in the 1980s.5 ) Second, language translation models began to report real gains, using very large corpuses of training data and computational resources to train models on them, in 2015. Suddenly good automated translations, not perfect but good enough to perfect manually, became available. The general acceleration of data gathering made possible by the internet was an important factor here. In both cases very large models were key, with millions, then billions, now a trillion or more, parameters weights fitted via training on huge data sets. Affordable repurposed Graphical Processing Units (GPUs) capable of massively parallel processing make fitting these models a realistic activity.6
Proliferation of parameters, and the lack of any substantial theory about the world, was always a drawback to neural networks in their early days, and is still poorly understood formally. Usually this sort of thing leads to overfitting of models on noise, leading to a decline in performance on new data. However in these applications, adding more parameters just continued to improve performance in practice, and this trend shows no sign of abating. Evidently the modeling technque determines when overfitting happens, which cannot naively be deduced from simple parameter counts. Such models are currently known generically and misleadingly as Large Language Models (LLMs) but since they now apply far beyond language, as general token-prediction systems, are better described as neural networks at scale.
Another breakthrough followed in 2017 with the invention of model ‘transformers’ for LLMs.7 These allow knowledge obtained from training on one dataset (a set of weights) to be transferred to other domains. Using this technique, generalized from the computer vision field and augmented with a novel neural net technique called ‘self-attention’, it is no longer necessary to start from scratch in every new application. Previously established pattern recognition encoded in a model can be used as a starting point and then augmented as needed.
3 Beadle Features
Beadle, named for the great American geneticist and Nobelist George Beadle (1903–1989),8 is an AI system that allows users to examine their personal DNA data and learn about genomics as they ask questions about that DNA. An important design goal was to supply concise to-the-point answers without the sort of lecturing, hedging and waffling that is unfortunately characteristic of general AI systems. Beadle does not condescend to its users. The system does not pretend to omniscience, or even genuine intelligence; it just tries to be useful. Current features of the system include
A chat environment populated by one or more personae that answer the user’s questions;
An extensive knowledge base of the genomics literature;
Access to a catalog of Genome-Wide Association Studies (GWAS);
The ability to summarize and discuss uploaded user DNA data;
Mechanisms for ensuring that the responses are factual and that the discussion stays within the genomics domain;
Automatic suggestions of topics for further discussion.
The system is currently implemented using multiple models with extensive customization and other logic. To the user, Beadle presents a familiar chat interface where one can engage in dialog with one or multiple personae. Currently available characters are
The Scientist,
The Skeptic,
The Enthusiast,
Traitwell Support.
When multiple personae are present, the Scientist is the central character that answers most of the user’s questions, but the system also uses the dialog history to help select the next speaker. The personae can also interact with each other. They allow Beadle to highlight the uncertainty of much scientific knowledge (the Skeptic) and the vast possibilities provided by recent advances in genomics (the Enthusiast). They also encourage critical thinking about open questions, of which there are many in the genetics field.
Dialog replies are generated by a model with access to the entire dialog history. The model also uses system messages that are invisible to the user, containing instructions that shape the personality of the active persona as well as content retrieved from knowledge sources external to the model. Those sources include a continually updated database of Genome-wide Association Study (GWAS) results for specific genes.
After completing a reply, the system analyzes it and extracts a list of the genomics topics mentioned. This allows Beadle to present the user with suggestions (’topic buttons’) for things to talk about next. Clicking on one of the suggestions generates a new question and moves the conversation forward. This is a convenience for the user and enables rapid conversational flow.
When Beadle answers user queries, its knowledge is not limited to that encoded in the operational model. Instead, it is extended with content retrieved from a large knowledge base of genomics and heritability literature, expertly curated. This is an example of retrieval-augmented generation (RAG), a highly effective technique for adding domain knowledge to an AI system.9 In addition to extending the system’s knowledge, the enhanced knowledge helps shape the tone and style of the output to emphasize cool-headed objectivity.10
A key feature of the system is allowing users to explore their own DNA data, informed by Beadle’s knowledge of genomics. The system can explain the user’s genetic sequence. In the absence of actual user DNA data, sample data is used for purposes of illustration.
Beadle is a genomics expert system so it limits the conversation to factual discussion within its domain of competence. It does not try to be ‘all things to all men (women or robots)’. To achieve this, it classifies user questions and rejects them politely if they seem to be about
Ethics or how the world ought to be, or
Topics not related to genomics.
In rare cases it is possible to make mistakes in this classification, but the user may always rephrase the question less ambiguously.
Answering complex queries can take time. The user’s subjective impression of performance is improved by providing information about the progress of system activities, with some diverting banter thrown in for fun.
4 How Accurate is Beadle?
An important topic for research in the general field of LLMs is the problem of hallucinations. The models predict the next ‘token’ for their application based on the trained model and the given context. The most plausible token is selected. Due to information compression and the need for prediction of previously unseen cases and scenarios, the most plausible token need not be the accurate one. Eveny now and then such systems may just make things up unless they are disciplined. In order to limit hallucinations and inconsistencies Beadle use a ‘Chain of Verification’ technique. It may be summarized as ‘rethink that before you speak’. This takes a little longer but boosts accuracy of its responses considerably. The compromise seems well worth it.11

Beadle is free to use if you have already had your DNA tested by Traitwell or by other genetic testing companies such as 23andMe, Ancestry, FamilyTreeDNA, Living DNA, and Nebula Genomics. It’s the a first-of-its-kind AI-powered chatroom for you to ask questions about your own DNA so get started today at http://traitwell.com/beadle.
References
McCulloch, Warren S. and Walter Pitts (1943). “A logical calculus of the ideas immanent in nervous activity”. In: The Bulletin of Mathematical Biophysics 5.4 (Dec. 1943), pp. 115–133.
Hebb, Donald O. (1949). The Organization of Behavior: A Neuropsychological Theory. New York: Wiley, 1949.
Minsky, Marvin and Seymour Papert (1969). Perceptrons: An Introduction to Computational Geometry. Cambridge, MA: MIT Press, 1969.
Rumelhart, David E., Geoffrey E. Hinton, and Ronald J. Williams (1986). “Learning representations by back-propagating errors”. In: Nature 323.6088 (1986), pp. 533–536.
Berg, Paul and Maxine Singer (2003). George Beadle, An Uncommon Farmer: The Emergence of Genetics in the 20th Century. CSHL Press, 2003, p. 383. isbn: 9780879696887.
Belanger, Jay and Dorothy Stein (2005). “Shadowy vision: spanners in the mechanization of mathematics”. In: Historia Mathematica 32.1 (Feb. 2005), pp. 76–93.
Hastie, Trevor, Robert Tibshirani, and Jerome Friedman (2009). The Elements of Statistical Learning: Data Mining, Inference, and Prediction. 2nd ed. Springer Series in Statistics. Springer, 2009. isbn: 978-0387848570.
Hinton, Geoffrey E. et al. (2012). “Improving neural networks by preventing co-adaptation of feature detectors”. In: arXiv preprint arXiv:1207.0580 (2012).
LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton (2015). “Deep Learning”. In: Nature 521.7553 (2015), pp. 436–444.
Vaswani, Ashish et al. (2017). “Attention Is All You Need”. In: Advances in Neural Information Processing Systems 30 (2017), pp. 5998–6008.
Lewis, P., E. Perez, A. Piktus, et al. (2020). “Retrieval-augmented generation for knowledge-intensive nlp tasks”. In: Advances in Neural Information Processing Systems 33 (2020), pp. 9459–9474.
Wang, X. et al. (2022). “Self-consistency improves chain of thought reasoning in language models”. In: arXiv preprint arXiv:2203.11171 (2022).
Wei, J., X. Wang, D. Schuurmans, et al. (2022). “Chain-of-thought prompting elicits reasoning in large language models”. In: arXiv preprint arXiv:2201.11903 (2022).
Bishop, Christopher M. and Hugh Bishop (2023). Deep Learning. Foundations and Concepts. Springer, 2023.
1Belanger and Stein 2005.
2McCulloch and Pitts 1943; Hebb 1949.
3Minsky and Papert 1969,Hastie, Tibshirani, and Friedman 2009.
4LeCun, Bengio, and G. Hinton 2015; C. M. Bishop and H. Bishop 2023.
5Rumelhart, G. E. Hinton, and Williams 1986.
6G. E. Hinton et al. 2012.
7Vaswani et al. 2017.
8Berg and Singer 2003.
9Lewis, Perez, Piktus, et al. 2020.
10Lewis, Perez, Piktus, et al. 2020.
11Wang et al. 2022; Wei, Wang, Schuurmans, et al. 2022.
We are entering the Golden age of fast seq reading at the table top scale. Chuck is introducing critical tech that prevents confusion and builds consistent AI results that hopefully will become a new standard for personalized medicine.